The 2023 “Accelerate State of DevOps Report” has provided several substantial insights. Here are the four main takeaways, delved into with more detail:
Burnout and the Underrepresented:
The report has identified a worrying link: there’s a correlation between the quality of documentation work and increased burnout, especially among those who identify as underrepresented. The data suggests that these individuals might be taking on a significant portion of such tasks. Businesses need to re-evaluate work distribution mechanisms to ensure fairness and avoid undue stress on specific teams or individuals.
The Significance of Documentation:
The report doesn’t just highlight documentation as a task but underscores its pivotal role in organizational success. Effective documentation directly influences technical capabilities, team productivity, and overall performance. Businesses aiming to elevate their documentation practices can refer to resources like the Society for Technical Communications and Google’s technical writing courses. Investing time and resources in documentation isn’t just beneficial—it’s essential.
A Glimpse into Google’s SRE Approach:
As Google’s suite of products grew, there was a pressing need to scale their Site Reliability Engineering (SRE) roles. The challenge was to do so without compromising on efficiency or reliability. The report sheds light on how Google has evolved its SRE practices to meet this challenge, offering valuable lessons for businesses grappling with scalability issues.
Harnessing the Power of Cloud Computing:
The report makes it clear: it’s not just about using cloud computing, but how you use it that counts. Businesses that strategically harness flexible infrastructure see improvements across various performance metrics. Moreover, the report lists the essential characteristics of effective cloud computing, acting as a guide for organizations to maximize their cloud benefits.
Organisations are complex sociotechnical systems. And all organisations exist in various states of dysfunction all the time. Some parts of the organisation may briefly reach a “functional” state where everything works effectively, and everyone knows what is happening. But those states don’t exist for long. We can think of this as the organisational entropic force – the constant introduction of external and internal forces and changes mean that a functional state is rapidly drawn back to dysfunction.
We can constantly strive to reduce this dysfunction, and we should, but we must remember that there is no such thing as a truly, completely, consistently “functional” organisation, and there never will be.
These characteristics combine to foster agility, alignment, collaboration, and speed. Despite a large organisational size, this enables people to act more like a network of small, tightly-knit teams. By organising around the work to be done, rather than the lines and boxes of an org chart, teams avoid becoming siloed and disconnected from value. These terms are usually associated with software delivery or engineering teams, and the concepts are part of the DevOps cultures and practices in general, but SLAM teams are appropriate for use in many domains from engineering to healthcare, and education to armed forces.
The people closest to the problem have the best information necessary to accomplish the task. A self-organising team has the freedom to decide how the work gets done and who completes which tasks. The manager exists as a coach and guide, not as a dictator.
There’s a limit to the amount of information we can store in our mind and the limitations of our working memory make it difficult to manage the complexities and communication overhead of large groups. Working in large groups slows us down, subjects us to greater decision fatigue and often impedes our ability to build psychological safety and carry out experiments. A Lean team is limited in size to 7-9 members, reducing communication complexity and improving decision capability.
Autonomous teams move quickly. We enable autonomy and reduce the number of external dependencies by clarifying what decisions can be made by the team members.
Having all the skills required in the team to make decisions and carry out the work from start to finish is the key point behind cross-functional, multi-disciplinary teams. If the team need to go outside the group to ask for decision support or worse, execution help, the pace of work slows down dramatically and the ability of the team to support the product also diminishes.
However, I’ve always felt there were some key points missing from SLAM teams. A key element of high performing teams is how long they exist for. Sure, we can have high performing teams that form and disperse over short timescales, but it’s harder, becomes very tiring over longer periods of time, and short-lived teams will never reach the very high performance that a long-lived team will do. So how about we make some tweaks?
Self-organising
Lean
Long-Lived
Autonomous
Multidisciplinary
SLLLAM teams not only self-organise, make their own decisions, and possess only the required team members with the right skills, but exist for a long time. The products we build should exist for a long time (or as long as is required), and the team should exist for at least as long as the product exists.
There’s a lot of information (and misinformation) on the concept of “Platform as a Product” in respect to current thinking in DevOps and organisational dynamics, and this is where I’m gathering my thoughts on that.
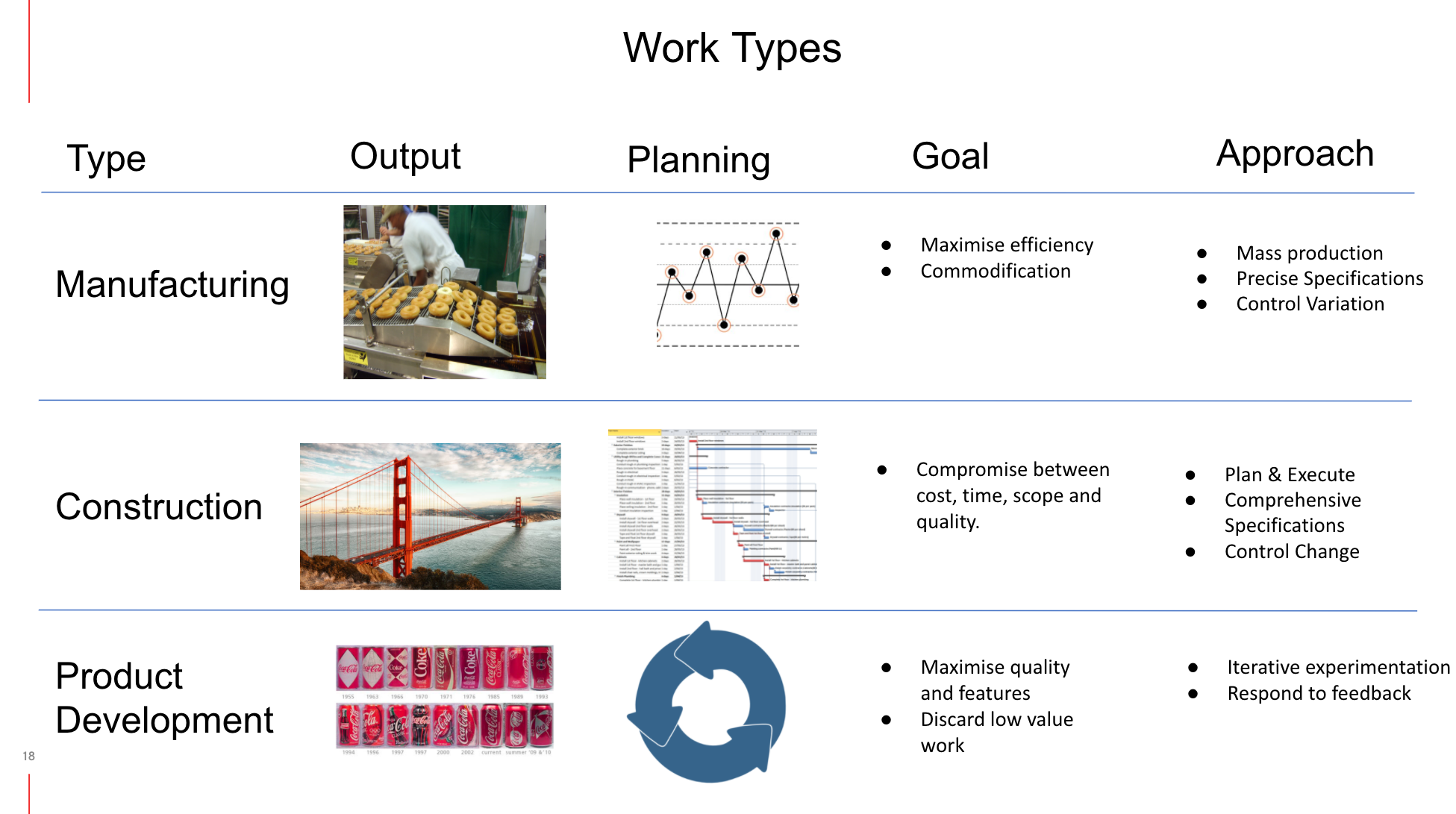
The core premise of “Platform as a Product” is to make explicit the need for a platform (low variability) to exist as a separate system from the customer-facing products (valuable variation**), and requires a long-lived platform team, practices, and budget to support it. Just to dive into this briefly: a platform is designed similarly to the manufacturing production line below – we want a platform to provide consistency and reliability (low variability). Indeed, it’s the consistency and reliability provided by a platform that enables a customer-facing product team to deliver products demonstrating high variation – which means we can rapidly deliver and test new features and changes.
The Platform as a Product internal operating model is not a perfect approach, and it certainly isn’t the “only” way to utilise the power of cloud platforms for development teams, but this approach has been shown to work for teams and organisations at various stages of maturity.
In my mind, a product has a few key characteristics:
It has users / customers, who are the key stakeholders in how the product should deliver value.
It’s long-lived.
It evolves over time in response to the needs and desires of the customers.
It’s “owned” by a person or team.
It only does what it needs to do. It as important to remove unused or under-used features as much as it is to evolve new features and functions.
A digital platform is a foundation of self-service APIs, tools, services, knowledge and support which are arranged as a compelling internal product. Autonomous delivery teams can make use of the platform to deliver product features at a higher pace, with reduced co-ordination.
In this article, I’ll try to outline my thinking in the rationale and benefits of adopting a Platform as a Product approach to technology and platform teams themselves. There are three core drivers behind the Platform as a Product approach, which are addressed in further detail below.
A platform should:
Reduce Developer Cognitive Load – software developers can be overloaded with system complexity, tooling, documentation, and organisational noise. The PaaP approach intends to reduce that cognitive load so that developers can focus on solving the problem and providing business value, quickly.
Reduce Operational Burden – this includes everything from reducing utilisation of people, reducing friction and handoffs, improving observability, to capacity management, and documentation. Basically – making everyone’s jobs easier alongside maximising the technology ROI for the business.
Optimise for Fast Flow – most, maybe all, organisations want to reduce the time it takes for an idea to begin returning value. This is true of commercial businesses, public sector, and other organisations such as charities. This involves optimising the technology for flow (automation, CI/CD tooling etc) as well as people, processes and practices. This is why we can’t separate the People from the Platform: the PaaP approach is not solely technological.
When we’re building software, we’re not manufacturing goods: i.e. we’re not producing the same thing over and over and trying to minimise variation. Neither are we building a single large deliverable, like a bridge or a custom car. We’re building a long-lived evolving product.
And that’s important to remember: products evolve over time, and there are elements of the product that we want to stay the same and benefit from stability, reliability and security as a result. But there are elements of the product that we want to change frequently, such as features, UX, and integrations. A platform as a product approach allows us to differentiate between the different needs and requirements of different parts of the system, and decouple those elements that need to change fast and often, from those that need to provide stability and reliability, and change less often. Different parts of the system demonstrate different levels of variability, and thats where platforms come in.
Cost of Delay
Part of the reason we want to be able to move quickly and introduce new features and changes is to reduce our Cost Of Delay – see the charts below:
The chart above shows the cost of delay for a simple product: the sooner you get the product to market, the sooner, you begin to realise value.
The chart here shows what happens if a competitor releases before you do. Not only do you miss out on the revenue due to the delay, but your competitor has grabbed the customers that you would have acquired if you’d released sooner. And because you can’t now get those customers, the loss is far greater: this is a case of missing the market window. So, let’s use platform as a product approach to reduce our cost of delay.
Software Delivery Performance
Nicole Forsgren, in her book, Accelerate, describes four key DevOps delivery metrics :
Lead time to change
Deployment frequency
Mean time to restore (MTTR)
Change failure rate
These metrics all describe capabilities that ultimately reduce your cost of delay, as well as customer satisfaction. So, let’s try to improve these metrics by implementing platform as a product approaches.
(Note: we shouldn’t be trying to reduce change failure rate or MTTR to zero – for all these metrics, we should be optimising them rather than striving to get them to zero or maximise deployment frequency.)
Handoffs and Flow
Handoffs reduce flow. Just ask these baton runners. Even with many hours of practice, a handoff can still result in failure and an impediment to speed. So, let’s reduce handoffs between team members by using a platform as a product so that developers can use and deploy systems on-demand.
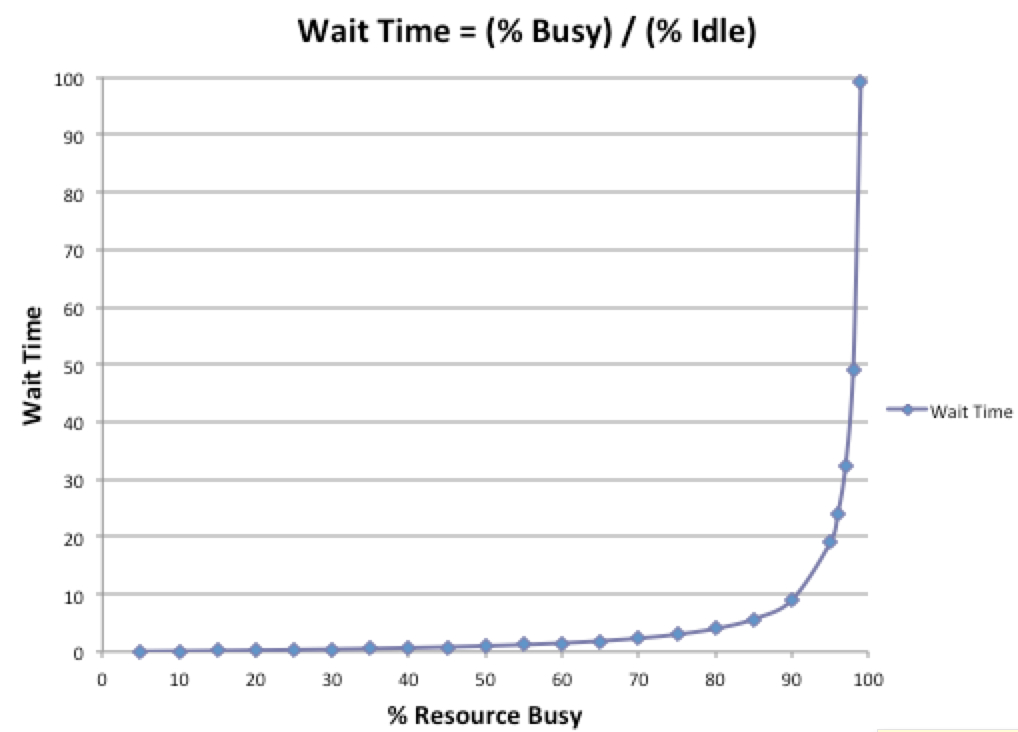
Not only do handoffs reduce flow, but if someone is busy, they can’t even accept the work you’re trying to give them. This is the only chart in the Phoenix project and describes the exponential impact on wait time as utilisation increases above ~80%. So, let’s reduce utilisation to acceptable levels at the same time as reducing handoffs (or eliminating them completely) by adopting the platform as a product approach and saving developers time that might be spent on maintenance and management of the underlying infrastructure.
Team Size
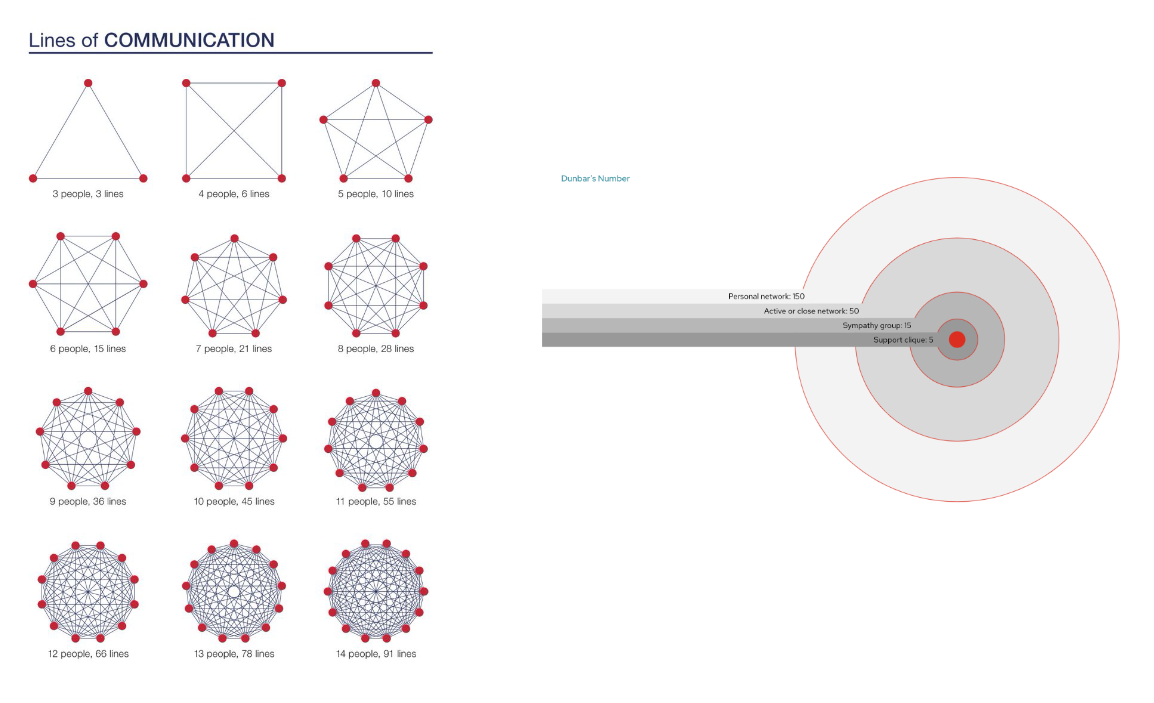
The two diagrams above show us that team sizes shouldn’t exceed certain numbers. Communication complexity shows us that above 8-9 team members (such as SLAM teams), communication becomes a blocker via exponentially increasing complexity. Dunbar’s theories also suggest (possibly as a result of communication complexity) that teams should remain below 15 people. So, let’s keep team sizes appropriately small by having a separate platform product team and development product teams.
Developer Cognitive Load
From Fraser, K. et al. (2018) “Cognitive Load Theory for debriefing simulations: implications for faculty development”, Advances in Simulation, 3(1). doi: 10.1186/s41077-018-0086-1.
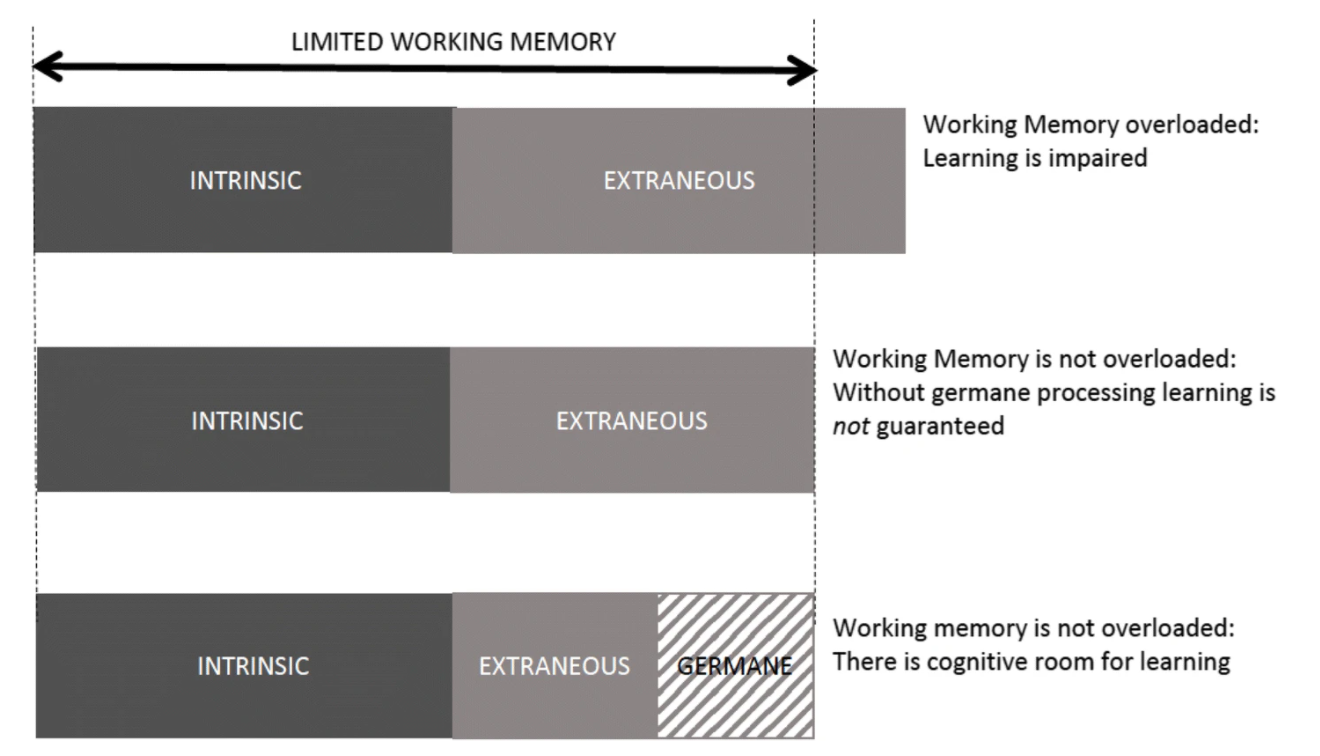
Cognitive load is critical in software development.
–Intrinsic cognition is all the stuff you already know, such as how to make a decent cup of tea. Where the teabags are, how to operate the kettle, how much milk to put in, etc.
–Extraneous cognition is all the external stuff that you need to find out or understand, such as where someone left the teabags because you can’t find them. It also includes “noise” such as distractions, how to operate unfamiliar equipment, or how to comply with regulatory requirements.
–Germane cognition is active learning and problem solving. That’s the stuff of real value – such as comparing Tetley tea to Yorkshire Tea in a taste test to find out which is better.* It’s also the process by which learning is transferred from short-term to long-term memory. It’s only through Germane cognition that we actually achieve anything or provide real value.
So, let’s minimise our extraneous cognitive load for developers and reduce the need for intrinsic cognitive load, so that the maximum effort can be put into the germane problem solving. The platform product does this by improving the developer experience (DevEx) and making it easier for developers to do what they need to do without referring to documentation or asking someone how to do something.
Thinnest Viable Platform
The platform itself needs only be as big as necessary to reduce the cognitive load of developers: so it may be sufficient for the platform to be a simple one-page repo describing how to deploy to AWS, or the platform could be a fully contained, multi-region, multi-cloud, self healing pipeline and platform. Matthew Skelton refers to this approach as the “Thinnest Viable Platform”.
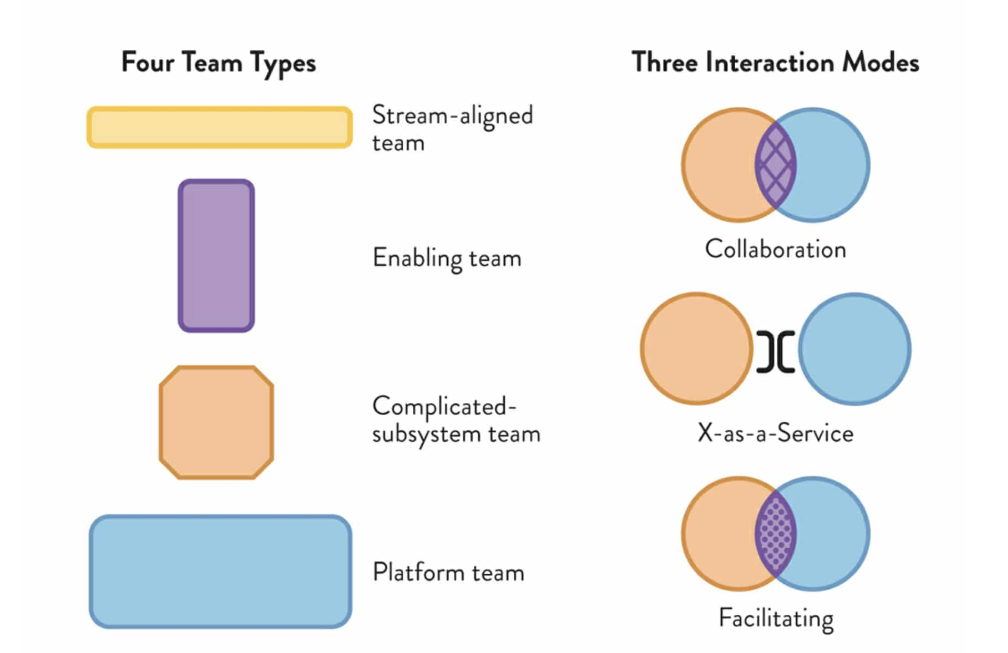
Team Topologies – credit Matthew Skelton and Manuel Pais
Matthew Skelton and Manuel Pais, in their book Team Topologies, describe four team types that enable fast flow in software development (and in other domains too). We won’t go into all four types and the three interaction modes here – there’s a ton of great information on the Team Topologies website. The platform team is essentially just like any other stream-aligned team, except their product is the platform itself, and their customers are the developers who use it.
Personal note: I’m uncomfortable with the premise of teams in an organisation categorising other teams as customers or suppliers because it can subordinate one team to another. I worry that language could lead us back to the bad old days of Ops teams being subordinate to Dev teams and a reversion back to silos. Instead, I suggest that you can use this concept to determine the boundaries of teams and create “Team APIs” and social contracts to surface and make explicit how teams communicate with each other.
Platform As A Product
I would strongly advise also looking at internalising service design capabilities and expertise to help teams design and build the platform. The platform as a product approach is fundamentally a practice to enable improved efficiency, improved product quality and reliability and faster speed to market, via reducing cognitive load for developers, faster flow of work, reduced handoffs, and enabling developers to focus on delivering value.
Criticisms of the Platform as a Product Approach
This approach isn’t a silver bullet. As with any framework or defined practice, it should be considered as a stage of a journey, and it may well be the case that very mature and highly capable technology delivery teams don’t require this approach, and can adopt a polycentric, shared commons approach that doesn’t require the platform to have a dedicated team, but distributes ownership across multiple teams. Check out Jabe Bloom on the Boundaryless podcast if you’re interested further – Platforming inside and between organizations: differentiation, scale, and scope.
However, I believe that most teams are not yet at that stage of maturity or capability, and it may take a long time to get there, so I feel that the Platform as a Product approach is a valid and effective path to high performance and effective delivery for most organisations.
If you’d like to find out more about this approach, join a workshop to enable your teams to adopt it, or find out more about the ways to evolve your organisational dynamics and team structures, get in touch with me, or hit up Matthew Skelton and the folks at Conflux who can help to power up your people, processes and technology.
Coming soon – the platform as a product playbook.
*Obviously we don’t actually need to run that experiment, Yorkshire Tea is clearly better.
Hybridisation in biological systems often creates a phenomena known as heterosis (also known as “hybrid vigour”): where the combining of two distinct varieties or genotypes results in a far stronger, more vigorous offspring, even though the resulting hybrid is usually sterile. Many commercial crop varieties are based on this principle, and the mule is a good example too, as the offspring of a male donkey and a female horse.
I’ve also been thinking about “hybrid” ways of working, and whether this kind of hybridisation also results in stronger and “better” outcomes. It’s much, much harder to create successful hybrid working systems and environments, but if we get it right, it allows us to exploit the benefits of both: the time saving efficiencies and comfort of remote and home working, combined with the power of high-bandwidth, in-person collaboration. But done badly, it results in the exclusion of individuals dialling in remotely to an in-person meeting, unpredictable travel patterns and lack of habit and ritual formation that’s so important to a high performing team.
If we’re going to make hybrid work, work for us, we need to be very intentional in designing the systems, processes, environments and practices that we use. And we must adopt an experimental approach, constantly evaluating and re-evaluating our decisions in order to keep, improve, or discard them in response to feedback.
Hybridisation of work can make us stronger, but only if we’re intentional and humble in our approach. If we are not, we risk degrading our outcomes as well as burning out our people.
Maybe the sterility of the outcome is where the analogy ends however!

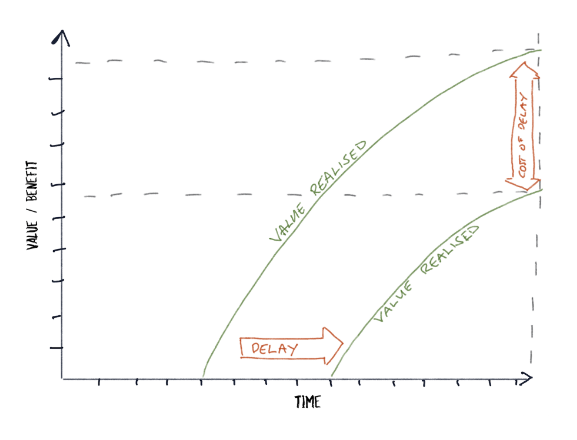 The chart above shows the cost of delay for a simple product: the sooner you get the product to market, the sooner, you begin to realise value.
The chart above shows the cost of delay for a simple product: the sooner you get the product to market, the sooner, you begin to realise value.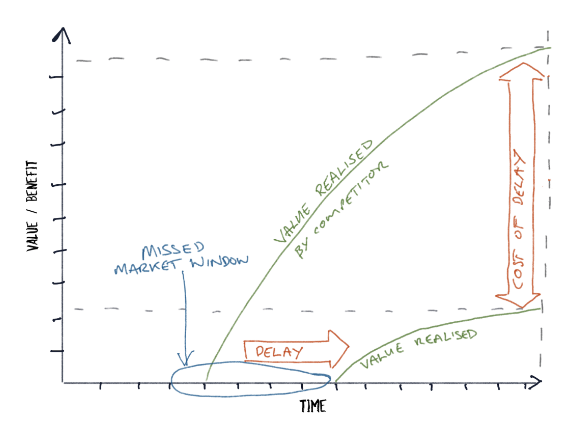 The chart here shows what happens if a competitor releases before you do. Not only do you miss out on the revenue due to the delay, but your competitor has grabbed the customers that you would have acquired if you’d released sooner. And because you can’t now get those customers, the loss is far greater: this is a case of missing the market window. So, let’s use platform as a product approach to reduce our cost of delay.
The chart here shows what happens if a competitor releases before you do. Not only do you miss out on the revenue due to the delay, but your competitor has grabbed the customers that you would have acquired if you’d released sooner. And because you can’t now get those customers, the loss is far greater: this is a case of missing the market window. So, let’s use platform as a product approach to reduce our cost of delay.