
As a DevOps engineer, you’ve achieved greatness. You’ve containerised everything, built your infrastructure and systems in the cloud and you’re deploying every day, with full test coverage and hardly any outages. You’re even starting to think you might really enjoy your job.
Then why are your compliance teams so upset?
Let’s take a step back. You know how to build secure applications, create back ups, control access to the data and document everything, and in general you’re pretty good at it. You’d do this stuff whether there were rules in place or not, right?
Not always. Back in the late 90’s, a bunch of guys in suits decided they could get rich by making up numbers in their accounts. Then in 2001 Enron filed for bankruptcy and the suits went to jail for fraud. That resulted in the Sarbanes-Oxley Act, legislation which forced publicly listed firms in the US to enforce controls to prevent fraud and enable effective audits.
Sarbanes-Oxley isn’t the only law that makes us techies do things certain ways though. Other compliance rules include HIPAA, ensuring that firms who handle clinical data do so properly; GDPR, which ensures adequate protection of EU citizens’ personal data; and PCI-DSS, which governs the use of payment card data in order to prevent fraud (and isn’t a law, but a common industry standard). Then there are countless other region and industry specific rules, regulations, accreditations and standards such as ISO 27001 and Cyber Essentials.
Aside from being good practice, the main reason you’d want to abide by these rules is to avoid losing your job and/or going to jail. It’s also worth recognising that demonstrating compliance can provide a competitive advantage over organisations that don’t comply, so it makes business sense too.
The trouble is, compliance is an old idea applied to new technology. HIPAA was enacted in 1996, Sarbanes-Oxley in 2002 and PCI DSS in 2004 (though it is frequently updated). In contrast the AWS EC2 service only went out of beta in late 2008, and the cloud has we know it has been around for just a few years. Compliance rules are rarely written with cloud technology in mind, and compliance teams sometimes fail to keep up to date with these platforms or modern DevOps-style practices. This can make complying with those rules tricky, if not downright impossible at times. How do you tell an auditor exactly where your data resides, if the only thing you know is that it’s in Availability Zone A in region EU-West-1? (And don’t even mention to them that one customer’s Zone A isn’t the same as another’s).
As any tech in a regulated industry will appreciate, compliance with these rules is checked by regular, painful and disruptive audits. Invariably, audits result in compliance levels looking something like a sine wave:
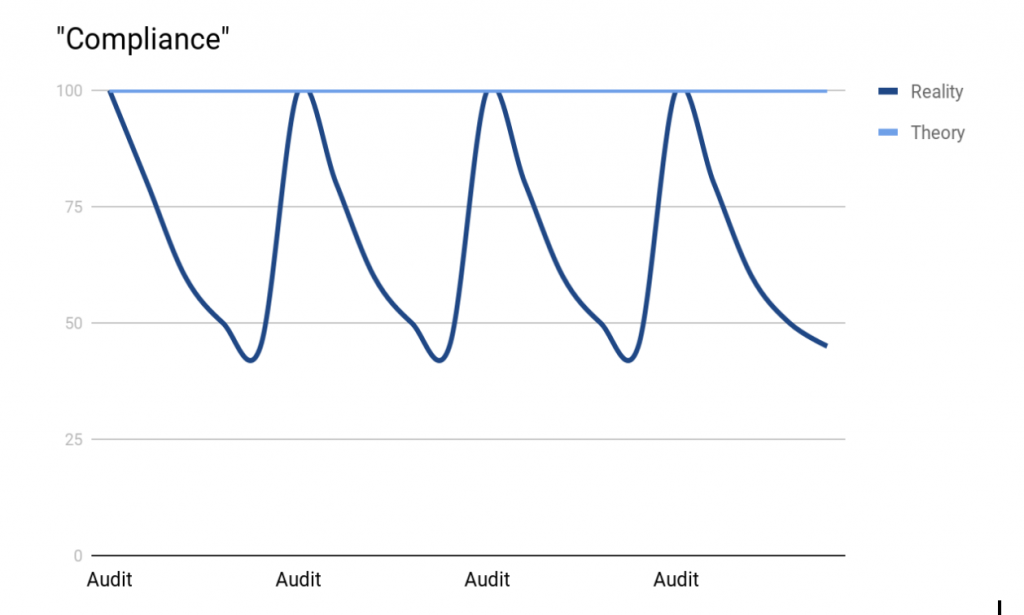
This is because when an audit is announced, the pressure is suddenly on to patch the systems, resolve vulnerabilities, update documents and check procedures. Once the audit is passed, everyone relaxes a bit, patching lags behind again, documentation falls out of date and the compliance state drifts away from 100%. This begs the question, if we only become non-compliant between audits, is the answer to have really, really frequent audits?
In a sense, yes. However, we can no longer accept that audits with spreadsheet tick box exercises, and infosec sign-off at deployment approval stage actually work. Traditional change management and compliance practices deliberately slow us down, with the intention of reducing the risk of mistakes.
This runs counter to modern DevOps approaches. We move fast, making rapid changes and allowing teams to be autonomous in their decision making. Cloud technology confuses matters even further. For example, how can you easily define how many servers you have and what state they’re in, if your autoscaling groups are constantly killing old ones and creating new ones?
From a traditional compliance perspective, this sounds like a recipe for disaster. But we know that making smaller, more frequent changes will result in lower overall risk than large, periodic changes. What’s more, we take humans out of the process wherever possible, implementing continuous integration and using automated tests to ensure quality standards are met.
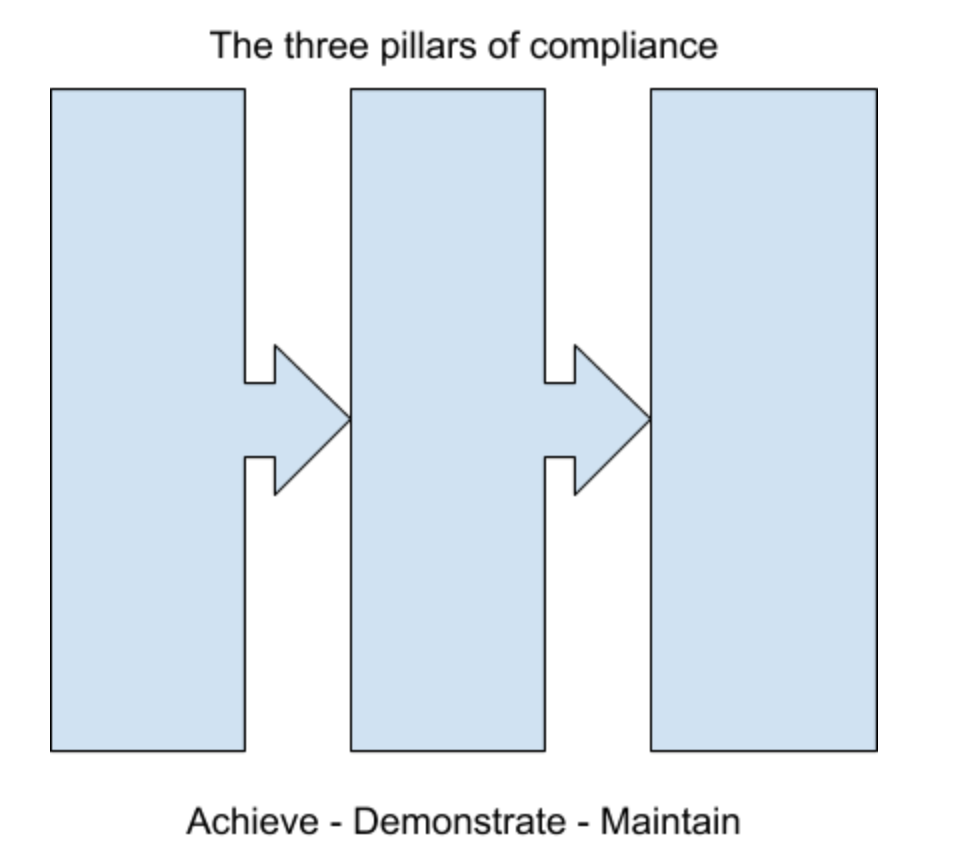
From a DevOps perspective, let’s consider compliance in three core stages. The first pillar represents achieving compliance. That’s the technical process of ensuring workloads and data are secure, everything is up to date, controlled and backed up. This bit’s relatively easy for competent techs like us.
The second pillar is about demonstrating that you’re compliant. How do you show someone else, without too much effort, that your data is secure and your backups actually work? This is a little more difficult, and far less fun.
The third pillar stands for maintaining compliance. This is a real challenge. How do you ensure that with rapid change, new technology, and multiple teams’ involvement, the system you built a year ago is still compliant now? This comes down to process and culture, and it’s the most difficult of the three pillars to achieve.
But it can be done. In DevOps and Agile culture, we shift left. We shorten feedback loops, decrease batch size, and improve quality through automated tests. This approach is now applied to security too, by embedding security tests into the development process and ensuring that it’s automated, codified, frictionless and fast. It’s not a great leap from there towards shifting compliance left too, codifying the compliance rules and embedding them within development and build cycles.
First we had Infrastructure as Code. Now we’re doing Compliance as Code. After all, what is a Standard Operating Procedure, if not a script for humans? If we can “code” humans to carry out a task in exactly the same way every time, we should be able to do it for machines.
Technologies such as AWS Config or Inspec allow us to constantly monitor our environment for divergence from a “compliant” state. For example, if a compliance rule deems that all data at rest is encrypted, we can define that rule in the system and ensure we don’t diverge from it – if something, human or machine, creates some unencrypted storage, it will be either be flagged for immediate attention or automatically encrypted.
One of the great benefits of this approach is that the “proof” of compliance is baked into your system itself. When asked by an auditor whether data is encrypted at rest, you can reassure them that it’s so by showing them your rule set. Since the rules are written as code, the documentation (the proof) is the control itself.
If you really want your compliance teams to love you (or at least quit hassling you), this automation approach can be extended to documentation. Since the entire environment can be described in code at any point in time, you can provide point-in-time documentation of what exists in that environment to an auditor, or indeed at any point in time previously, if it’s been recorded.
By involving your compliance teams in developing and designing your compliance tools and systems, asking what’s important to them, and building in features that help them to do their jobs, you can enable your compliance teams to serve themselves. In a well designed system, they will be able to find the answers to their own questions, and have confidence that high-trust control mechanisms are in place.
Compliance as Code means that your environment, code, documentation and processes are continuously audited, and that third, difficult pillar of maintaining compliance becomes far easier:
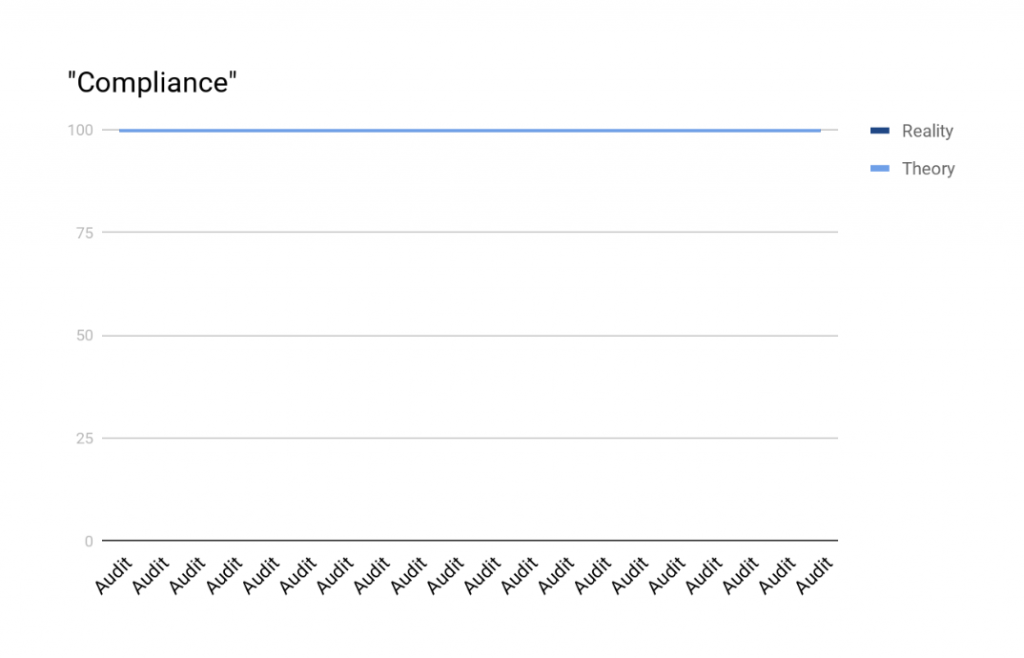
This is what continuous compliance looks like. Achieve this, and you’ll see what a happy compliance team looks like too.