
The Links Between Psychological Safety, Resilience Engineering and DevOps
Note: since writing this, I’ve learned a lot more about resilience engineering and its relation to DevOps and psychological safety.
Psychological safety is cited as the key factor in team performance by numerous studies including Google’s Project Aristotle and the DORA/Google State Of DevOps Reports. The evidence shows that teams that operate in psychologically safe environments where they can present their true selves at work, take risks, admit mistakes, and ask for support from their teammates, significantly outperform other organisations.

However, establishing psychological safety is rarely prioritised by delivery-focussed leaders who use output-oriented metrics. Instead, these leaders tend to focus on objectives, metrics, and modern practices such as value-stream alignment and cross-functional teams. While these have great value, and will go some way, or indeed a long way, to drive performance and delivery, they are not the full picture.
It can be very challenging, particularly for less experienced leaders, or capable leaders in difficult circumstances, to build and facilitate psychologically safe environments. This is particularly true in technologically-oriented organisations where the domain is complex and failure is explicit, obvious and can generate a large blast radius.
Mistakes happen. They must happen.
In a psychologically unsafe team, a software engineer who makes a mistake in a complex system and releases a small flaw into production that later causes an outage may be blamed for the mistake. The flaw will be easily attributable, and the impact of the outage can be significant. In many organisations, the resultant fear of error can dramatically slow down the rate of change and speed to market.
Of course, the converse is not appealing either; it’s not acceptable to tolerate errors, outages, and mistakes. Speed to market with a faulty product or service may be equally as bad as a significant delay to reach the market. Customers do not tolerate poor quality services, so we need to build high quality services and do it at velocity. This delivery at pace is one of the key tenets of DevOps, and an effective DevOps culture requires psychological safety.
Resilience Engineering and Psychological Safety
In my work on psychological safety in high performance teams, I’m often asked about how to achieve it, and whilst there are many general approaches that overlap significantly with principles of excellence in servant (or empathetic) leadership, there are also specific actions and approaches that are suitable specifically for technology teams. Here, we’re going to drill down into one of the key aspects of a DevOps approach: Resilience Engineering, and how psychological safety is a fundamental component of resilience.
Resilience Engineering is a field of study that emerged from cognitive system engineering in the early 2000s, largely in response to NASA events in 1999 and 2000, including the failure of the Mars Climate Orbiter. It is defined as “The intrinsic ability of a system to adjust its functioning prior to, during, or following changes and disturbances, so that it can sustain required operations under both expected and unexpected conditions.” Erik Hollnagel

Resilience Engineering is the intentional engineering of a system (a sociotechnical system, such as a community, organisation, or nation) to anticipate, detect and respond to both external and internal changes, planned or unplanned, to the system itself and continue to operate whilst change occurs.
Very little theory within this domain has been generated that doesn’t emerge from studies of real work; Resilience Engineering exists within high-stakes domains such as aviation, construction, surgery, military agencies and law enforcement and is becoming more visible in DevOps and Digital Transformation.
There is a difference between robustness and resilience engineering, as described by David Woods, Professor, Integrated Systems Engineering Faculty, Ohio State University. Technological measures such as autoscaling, failovers, retries and queues, for example, only really contribute to robustness, not resilience:
- Decoupling and reducing dependencies between components
- Utilising microservices and containerisation
- Autoscaling applications based on demand
- Creating self-healing applications and systems
- Using monitoring and visibility tools to facilitate responses to out-of-bounds events
- Adopting error budgeting instead of (or in addition to) uptime measures
- Using automated code testing, continuous integration and advanced deployment practices

These approaches extend to concepts such as chaos engineering. This is where flaws and interruptions are intentionally introduced in order to examine how the system behaves and help engineers identify how they can improve it.
DevOps practices such as these help to build and improve psychological safety, through facilitating safe risk taking , and resilience Engineering requires psychological safety to be present, because it is only psychological safety that enables people (the adaptable component of a system) to anticipate, respond and adapt to changes and challenges.
The formation of DevOps teams
As a new DevOps-oriented team moves through Tuckman’s Forming-Storming-Norming-Performing cycle, it relies more and more on cultures and practices that facilitate risk taking and admitting mistakes. If these practices are not embedded, the team will never be able to progress to the “performing” stage, because high performance explicitly requires innovation, and therefore, risk taking. Without psychological safety, teams will cycle around the Storming and Norming phases as elements change in or around the team, such as people leaving or joining.
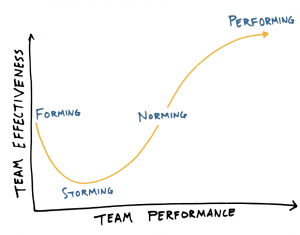
It is only once an engineering team reaches the high performing stage that they can truly deliver high quality services at velocity. By utilising resilience engineering principles and DevOps practices, engineers are supported to take risks, experiment, deploy changes and recover quickly. They can feel comfortable in the knowledge that if something did go wrong, they’d find out straight away, before customers start calling. These practices, far from being so-called “soft” skills, are measurable by solid metrics that describe velocity whilst maintaining reliability, such as Change Rate, Mean Time Between Failures (MTBF) and Mean Time To Restore (MTTR).
Engineering Team Topologies
Resilience Engineering echoes many capabilities with the concept of Site Reliability Engineering (SRE), introduced by Ben Traynor’s team at Google in 2004. SRE practices and capabilities may be implemented by an expert, dedicated, shared SRE team, or it may suit your organisation to embed an SRE function into each stream-aligned (SA) team if the products and systems are large enough to justify it. Alternatively, it may be feasible to empower software engineers themselves to carry out SRE responsibilities if your systems are small enough.
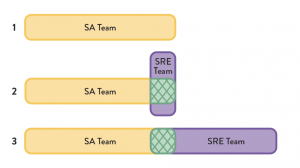
In addition to expert leadership practice, well organised teams, adopted shared values, systemic root causes being diagnosed in retrospectives, and an embrace of continuous improvement, we must adopt capabilities that empower team members to carry out their roles without fear of failure. In a technology team, those capabilities are the very same ones that enable high velocity change, security, and reliability.
For more information regarding technology team organisation, Matthew Skelton and Manuel Pais explore in great depth how software teams can be organised to deliver most value, safety, and performance in their book “Team Topologies”, where they examine how the concepts of Conways Law, Cognitive Load and Organisational Evolution converge.
Resilience engineering is about entire organisations, not just technology.
Whatever team you’re on, or whatever team you lead, considering resilience engineering principles will improve delivery, safety, happiness, and performance. This enables people to work without fear, psychologically safe in the knowledge that errors do not flow downstream. This place is where true high performance, speed to market, quality and innovation happens.
Psychological safety is also a core component of Agile delivery teams, as it fundamentally enables truthful communication, response to change, and the ability to make mistakes and innovate.
Build your own high performing teams with psychological safety
For more information about high performance teams, psychological safety, DevOps, or any of the other concepts covered in this article, get in touch. I’m always for collaboration, speaking at events, podcasts, or other ways to get involved and help teams become more productive, safer, and most importantly, happier.
Download a complete Psychological Safety Action Pack full of workshops, tools, resources, and posters to help you measure, build, and maintain Psychological Safety in your teams.
@tom_geraghty
