It’s not that easy to find all the annual state of DevOps reports, partly because they forked in 2017 between Puppet and Google/DORA. Below I’ve listed each report by year, and I’m in the process of listing all the key findings from each report. Some reports provide greater insights than others.
The first report was in 2013, and showed quite clearly that adopting DevOps practices resulted in technological and business improvements. Along the way, Puppet and Google / DORA joined forces, parted ways, and now (as of writing in 2021) there are two State of DevOps Reports, and the focus has broadened to SRE, Organisational Culture, Security, and even Documentation.
- Respondents from organisations that implemented DevOps reported improved software deployment quality and more frequent software releases.
- DevOps enables high performance by increasing agility and reliability. High performing organisations ship code 30x faster and complete those deployments 8,000 times faster than their peers. They also have 50% fewer failures and restore service 12 times faster than their peers.
- Organisations that have implemented DevOps practices are up to five times more likely to be high-performing than those that have not. In fact, the longer organisations have been using DevOps practices, the better their performance: The best are getting better.
- Strong IT performance is a competitive advantage. Firms with high-performing IT organisations were twice as likely to exceed their profitability, market share and productivity goals.
- DevOps practices improve IT performance. IT performance strongly correlates with well-known DevOps practices such as use of version control and continuous delivery.
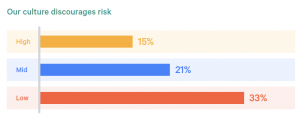
- Organizational culture matters. Organizational culture is one of the strongest predictors of both IT performance and overall performance of the organisation. High-trust organisations encourage good information flow, cross-functional collaboration, shared responsibilities, learning from failures and new ideas; they are also the most likely to perform at a high level.
- Job satisfaction is the No. 1 predictor of organisational performance. Job satisfaction includes doing work that’s challenging and meaningful, and being empowered to exercise skills and judgment. Where there is job satisfaction, employees bring the best of themselves to work: their engagement, their creativity and their strongest thinking.
- High-performing IT organisations deploy 30x more frequently with 200x shorter lead times; they have 60x fewer failures and recover 168x faster. Failures are unavoidable, but how quickly you detect and recover from failure can mean the difference between leading the market and struggling to catch up with the competition.
- Lean management and continuous delivery practices create the conditions for delivering value faster, sustainably. This results in higher quality, shorter cycle times with quicker feedback loops, and lower costs. These practices also contribute to creating a culture of learning and continuous improvement.
- High performance is achievable whether your apps are greenfield, brownfield or legacy. As long as systems are architected with testability and deployability in mind, high performance is achievable.
- IT managers play a critical role in any DevOps transformation. Managers can do a lot to improve their team’s performance by ensuring work is not wasted
and by investing in developing the capabilities of their people. - Diversity matters. Research shows that teams with more women members have higher collective intelligence and achieve better business outcomes.
- Deployment pain can tell you a lot about your IT performance. Where code deployments are most painful, you’ll find the poorest IT performance, organisational performance and culture.
- Burnout can be prevented, and DevOps can help. Burnout is associated with pathological cultures and unproductive, wasteful work.
- High-performing organisations are decisively outperforming their lower-performing peers in terms of throughput. High performers deploy 200 times more frequently than low performers, with 2,555 times faster lead times. They also continue to significantly outperform low performers, with 24 times faster recovery times and three times lower change failure rates.
- High performers have better employee loyalty, as measured by employee Net Promoter Score (eNPS). Employees in high-performing organisations were 2.2 times more likely to recommend their organisation to a friend as a great place to work, and 1.8 times more likely to recommend their team to a friend as a great working environment. Other studies have shown that this is correlated with better business outcomes.
- Improving quality is everyone’s job. High-performing organisations spend 22 percent less time on unplanned work and rework. As a result, they are able to spend 29 percent more time on new work, such as new features or code. They are able to do this because they build quality into each stage of the development process through the use of continuous delivery practices, instead of retrofitting quality at the end of a development cycle.
- High performers spend 50 percent less time remediating security issues than low performers. Through better integrating information security objectives into daily work, teams achieve higher levels of IT performance and build more secure systems. less time on unplanned work and rework.
- Taking an experimental approach to product development can improve your IT and organisational performance. The product development cycle starts long before a developer starts coding. Your product team’s ability to decompose products and features into small batches; provide visibility into the flow of work from idea to production; and gather customer feedback to iterate and improve will predict both IT performance and deployment pain.
- Transformational leaders share five common characteristics that significantly shape an organisation’s culture and practices, leading to high performance. The characteristics of transformational leadership — vision, inspirational communication, intellectual stimulation, supportive leadership, and personal recognition — are highly correlated with IT performance.
- High-performing teams continue to achieve both faster throughput and better stability. The gap between high and low performers narrowed for throughput measures, as low performers reported improved deployment frequency and lead time for changes, compared to last year. However, the low performers reported slower recovery times and higher failure rates. It’s possible that pressure to deploy faster and more often causes lower performers to pay insufficient attention to building in quality.
- Automation is a huge boon to organisations. High performers automate significantly more of their configuration management, testing, deployments and change approval processes than other teams. The result is more time for innovation and a faster feedback cycle.
- Loosely coupled architectures and teams are the strongest predictor of continuous delivery. If you want to achieve higher IT performance, start shifting to loosely coupled services — services that can be developed and released independently of each other — and loosely coupled teams, which are empowered to make changes.
- Lean product management drives higher organisational performance. Lean product management practices help teams ship features that customers actually want, more frequently. This faster delivery cycle lets teams experiment, creating a feedback loop with customers.
- DevOps drives business growth – maintaining a robust software delivery and operability function increases productivity, profitability, and market share.
- Cloud technology correlates with business performance – this is enabled by reliable and sustainable cloud infrastructure, utilised via cloud native patterns.
- Open source software improves performance – high-performing IT teams are 1.75 times more likely to use open-source applications.
- Functional outsourcing can be detrimental to software performance, and Elite Performers are rarely using it.
- Technical practices such as monitoring and observability, continuous testing, database change management, and the early integration of security in software development all enable organisational performance.
- DORA identified high-performing organisations in a range of profit, not-for-profit, regulated, and non-regulated industries. The industry you’re in doesn’t affect your ability to perform.
- Diversity in tech is poor, but improving, and teams with improved diversity demonstrate higher performance than those that don’t.
2018 – DORA (Accelerate):
- SDO (Software Delivery Organisation – i.e. development teams) performance unlocks competitive advantages. Those include increased profitability, productivity, market share, customer satisfaction, and the ability to achieve organisation and mission goals.
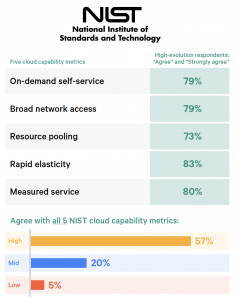
- How you implement cloud infrastructure matters. Proper (effective) usage of the public cloud improves software delivery performance and teams that leverage all of cloud computing’s essential characteristics are 23 times more likely to be high performers.
- Open source software improves performance. Open source software is 1.75 times more likely to be extensively used by the highest performers.
- Outsourcing by function is rarely adopted by elite performers and hurts performance. While outsourcing can save money, low-performing teams are almost 4 times as likely to outsource whole functions such as testing or operations than their highest-performing counterparts.
- Key technical practices drive high performance. These include monitoring and observability, continuous testing, database change management, and integrating security earlier in the SDLC.
- Industry doesn’t matter when it comes to achieving high performance for software delivery. High performers exist in both non-regulated and highly regulated industries alike.
- Doing DevOps well enables you to do security well.
- Integrating security deeply into the software delivery lifecycle makes teams more than twice as confident of their security posture.
- Integrating security throughout the software delivery lifecycle leads to positive outcomes.
- Security integration is messy, especially in the middle stages of evolution.
- The industry continues to improve, particularly among the elite performers.
- The best strategies for scaling DevOps in organisations focus on structural solutions that build community, including Communities of Practice.
- Cloud continues to be a differentiator for elite performers and drives high performance.
- To support productivity, organisations can foster a culture of psychological safety and make smart investments in tooling, information search, and reducing technical debt through flexible, extensible, and viewable systems.
- Heavyweight change approval processes, such as change approval boards, negatively impact speed and stability. In contrast, having a clearly understood process for changes drives speed and stability, as well as reductions in burnout.
- The industry still has a long way to go and there remain significant areas for improvement across all sectors.
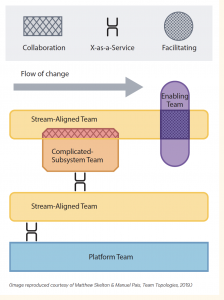
- Internal platforms and platform teams are a key enabler of performance, and more organisations are adopting this approach.
- Adopting a product approach over project-oriented improves performance and facilitates improved adoption of DevOps cultures and practices.
- Lean, automated, and people-oriented change management processes improve velocity and performance.
- Organisational dynamics must be considered crucial to transformation.
- Cloud-native approaches are critical. It is no good to simply move traditional workloads to the cloud.
- Shift security, compliance and change governance left, and include security stakeholders in all stages of value delivery.
- Culture change is key, and must be promoted from the very “top” as well as delivered from the “bottom”. Psychological safety is at the core of digital and cultural transformations.
- The “highest performers” continue to improve the velocity of delivery.
- Adoption of SRE practices improves wider organisational performance.
- Adoption of cloud technology accelerates software delivery and organisational performance. Multi-cloud adoption is also on the increase.
- Secure Software Supply Chains enable teams to deliver secure software quickly, safely and reliably.
- Documentation is important to being able to implement technical practices, make changes, and recover from incidents.
- Inclusive and generative team cultures improve resilience and performance.
- Generative Cultures are indicators of higher performance.
- Less experienced teams who implemented trunk-based development actually show less positive results than teams who do not use trunk-based development.
- Healthy, high-performing teams also tend to have good security practices broadly established.
- Software delivery performance alone does not predict organisational success. Excellent software delivery combined with high reliability (high DORA Metrics in this case) correlate with organisational success.