[This is a work in progress. If you spot an error, or would like to contribute, please get in touch]
The term “Resilience Engineering” is appearing more frequently in the DevOps domain, field of physical safety, and other industries, but there exists some argument about what it really means. That disagreement doesn’t seem to occur in those domains where Resilience Engineering has been more prevalent and applied for some time now, such as healthcare and aviation. Resilience Engineering is an academic field of study and practice in its own right. There is even a Resilience Engineering Association.
Resilience Engineering is a multidisciplinary field associated with safety science, complexity, human factors and associated domains that focuses on understanding how complex adaptive systems cope with, and learn from, surprise.
It addresses human factors, ergonomics, complexity, non-linearity, inter-dependencies, emergence, formal and informal social structures, threats and opportunities. A common refrain in the field of resilience engineering is “there is no root cause“, and blaming incidents on “human error” is also known to be counterproductive, as Sidney Dekker explains so eloquently in “The Field Guide To Understanding Human Error”.
Resilience engineering is “The intrinsic ability of a system to adjust its functioning prior to, during, or following changes and disturbances, so that it can sustain required operations under both expected and unexpected conditions.” Prof Erik Hollnagel
It is the “sustained adaptive capacity” of a system, organisation, or community.
Resilience engineering has the word “engineering” in, which makes us typically think of machines, structures, or code, and this is maybe a little misleading. Instead, maybe try to think about engineering being the process of response, creation and change.
Systems
Resilience Engineering also refers to “systems”, which might also lead you down a certain mental path of mechanical or digital systems. Widen your concept of systems from software and machines, to organisations, societies, ecosystems, even solar systems. They’re all systems in the broader sense.
Resilience engineering refers in particular to complex systems, and typically, complex systems involve people. Human beings like you and I (I don’t wish to be presumptive but I’m assuming that you’re a human reading this).
Consider Dave Snowden’s Cynefin framework:
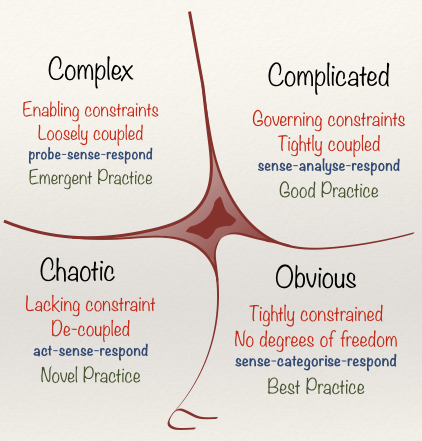
Systems in an Obvious state are fairly easy to deal with. There are no unknowns – they’re fixed and repeatable in nature, and the same process achieves the same result each time, so that we humans can use things like Standard Operating Procedures to work with them.
Systems in a Complicated state are large, usually too large for us humans to hold in our heads in their entirety, but are finite and have fixed rules. They possess known unknowns – by which we mean that you can find the answer if you know where to look. A modern motorcar, or a game of chess, are complicated – but possess fixed rules that do not change. With expertise and good practice, such as employed by surgeons or engineers or chess players, we can work with systems in complicated states.
Systems in a Complex state possess unknown-unknowns, and include realms such as battlefields, ecosystems, organisations and teams, or humans themselves. The practice in complex systems is probe, sense, and respond. Complexity resists reductionist attempts at determining cause and effect because the rules are not fixed, therefore the effects of changes can themselves change over time, and even the attempt of measuring or sensing in a complex system can affect the system. When working with complex states, feedback loops that facilitate continuous learning about the changing system are crucial.
Systems in a Chaotic state are impossible to predict. Examples include emergency departments or crisis situations. There are no real rules to speak of, even ones that change. In these cases, acting first is necessary. Communication is rapid, and top-down or broadcast, because there is no time, or indeed any use, for debate.
Resilience
As Erik Hollnagel has said repeatedly since Resilience Engineering began (Hollnagel & Woods, 2006), resilience is about what a system can do — including its capacity:
- to anticipate — seeing developing signs of trouble ahead to begin to adapt early and reduce the risk of decompensation
- to synchronize — adjusting how different roles at different levels coordinate their activities to keep pace with tempo of events and reduce the risk of working at cross purposes
- to be ready to respond — developing deployable and mobilizable response capabilities in advance of surprises and reduce the risk of brittleness
- for proactive learning — learning about brittleness and sources of resilient performance before major collapses or accidents occur by studying how surprises are caught and resolved
(From Resilience is a Verb by David D. Woods)
| Capacity |
Description |
| Anticipation |
Create foresight about future operating conditions, revise models of risk |
| Readiness to respond |
Maintain deployable reserve resources available to keep pace with demand |
| Synchronization |
Coordinate information flows and actions across the networked system |
| Proactive learning |
Search for brittleness, gaps in understanding, trade-offs, re-prioritisations |
Provan et al (2020) build upon Hollnagel’s four aspects of resilience to show that resilient people and organisations must possess a “Readiness to respond”, and states “This requires employees to have the psychological safety to apply their judgement without fear of repercussion.”
Resilience is therefore something that a system “does”, not “has”.
Systems comprise of structures, technology, rules, inputs and outputs, and most importantly, people.
“Resilience is about the creation and sustaining of various conditions that enable systems to adapt to unforeseen events. *People* are the adaptable element of those systems” – John Allspaw (@allspaw) of Adaptive Capacity Labs.
Resilience therefore is about “systems” adapting to unforeseen events, and the adaptability of people is fundamental to resilience engineering.
And if resilience is the potential to anticipate, respond, learn, and change, and people are part of the systems we’re talking about:
We need to talk about people: What makes people resilient?
Psychological safety
Psychological safety is the key fundamental aspect of groups of people (whether that group is a team, organisation, community, or nation) that facilitates performance. It is the belief, within a group, “that one will not be punished or humiliated for speaking up with ideas, questions, concerns, or mistakes.” – Edmondson, 1999.
Amy Edmondson also talks about the concept of a “Learning organisation” – essentially a complex system operating in a vastly more complex, even chaotic wider environment. In a learning organisation, employees continually create, acquire, and transfer knowledge—helping their company adapt to the un-predictable faster than rivals can. (Garvin et al, 2008)
“A resilient organisation adapts effectively to surprise.” (Lorin Hochstein, Netflix)
https://twitter.com/cyetain/status/1242926422869651458
In this sense, we can see that a “learning organisation” and a “resilient organisation” are fundamentally the same.
Learning, resilient organisations must possess psychological safety in order to respond to changes and threats. They must also have clear goals, vision, and processes and structures. According to Conways Law:
“Any organisation that designs a system (defined broadly) will produce a design whose structure is a copy of the organisation’s communication structure.”
In order for both the organisation to respond quickly to change, and for the systems that organisation has built to respond to change, the organisation must be structured in such a way that response to change is as rapid as possible. In context, this will depend significantly on the organisation itself, but fundamentally, smaller, less-tightly coupled, autonomous and expert teams will be able to respond to change faster than large, tightly-bound teams with low autonomy will. Pais and Skelton’s Team Topologies explores this in much more depth.
Engineer the conditions for resilience engineering
“Before you can engineer resilience, you must engineer the conditions in which it is possible to engineer resilience.” – Rein Henrichs (@reinH)
As we’ve seen, an essential component of learning organisations is psychological safety. Psychological safety is a necessary condition (though not sufficient) for the conditions of resilience to be created and sustained.
Therefore we must create psychological safety in our teams, our organisations, our human “systems”. Without this, we cannot engineer resilience.
We create, build, and maintain psychological safety via three core behaviours:
- Framing work as a learning problem, not an execution problem. The primary outcome should be knowing how to do it even better next time.
- Acknowledging your own fallibility. You might be an expert, but you don’t know everything, and you get things wrong – if you admit it when you do, you allow others to do the same.
- Model curiosity – ask a lot of questions. This creates a need for voice. By you asking questions, people HAVE to speak up.
Resilience engineering and psychological safety
Psychological safety enables these fundamental aspects of resilience – the sustained adaptive capacity of a team or organisation.:
- Taking risks and making changes that you don’t, or can’t, fully understand the outcomes of.
- Admitting when you made a mistake.
- Asking for help
- Contributing new ideas
- Detailed systemic cause* analysis (The ability to get detailed information about the “messy details” of work)
(*There is never a single root cause)
Let’s go back to that phrase at the start:
Sustained adaptive capacity.
What we’re trying to create is an organisation, a complex system, and sub systems (maybe including all that software we’re building) that possesses a capacity for sustained adaptation.
With DevOps we build systems that respond to demand, scale up and down, we implement redundancy, low-dependancy to allow for graceful failure, and identify and react to security threats.
Pretty much all of these only contribute to robustness.
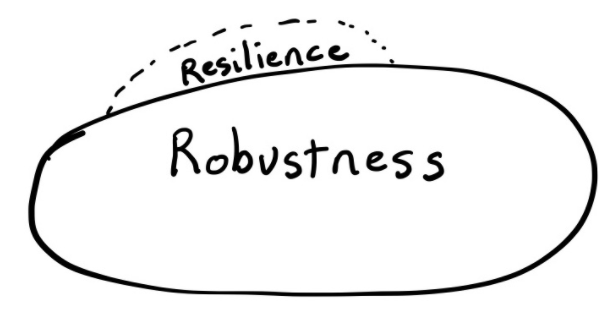
(David Woods, Professor, Integrated Systems Engineering Faculty, Ohio State University)
You may want to think back to the cynefin model, and think of robustness as being able to deal well with known unknowns (complicated systems), and resilience as being able to deal well with unknown unknowns (complex, even chaotic systems). Technological or DevOps practices that primarily focus on systems, such as microservices, containerisation, autoscaling, or distribution of components, build robustness, not resilience.
However, if we are to build resilience, the sustained adaptive capacity for change, we can utilise DevOps practices for our benefit. None of them, like psychological safety, are sufficient on their own, but they are necessary. Using automation to reduce the cognitive load of people is important: by reducing the extraneous cognitive load, we maximise the germane, problem solving capability of people. The provision of other tools, internal platforms, automated testing pipelines, and increasing the observability of systems increases the ability of people and teams to respond to change, and increases their sustained adaptive capacity.
If brittleness is the opposite of resilience, what does “good” resilience look like? The word “anti-fragility” appears to crop up fairly often, due to the book “Antifragile: Things that Gain from Disorder” by Nassim Taleb. What Taleb describes as antifragile, ultimately, is resilience itself.
I have my own views on this, but fundamentally I think this is the danger of academia (as in the field of resilience engineering) restricting access to knowledge. A lot of resilience engineering literature is held behind academic paywalls and journals, which most practitioners do not have access to. It should be of no huge surprise that people may reject a body of knowledge if they have no access to it.
Observability
It is absolutely crucial to be able to observe what is happening inside the systems. This refers to anything from analysing system logs to identify errors or future problems, to managing Work In Progress (WIP) to highlight bottlenecks in a process.
Too often, engineering and technology organisations look only inward, whilst many of the threats to systems are external to the system and the organisation. Observability must also concern external metrics and qualitative data: what is happening in the marketspace, the economy, and what are our competitors doing?
Resilience Engineering and DevOps
What must we do?
Create psychological safety – this means that people can ask for help, raise issues, highlight potential risks and “apply their judgement without fear of repercussion.” There’s a great piece here on psychological safety and resilience engineering.
Manage cognitive load – so people can focus on the real problems of value – such as responding to unanticipated events.
Apply DevOps practices to technology – use automation, internal platforms and observability, amongst other DevOps practices.
Increase observability and monitoring – this applies to systems (internal) and the world (external). People and systems cannot respond to a threat if they don’t see it coming.
Embed practices and expertise in component causal analysis – whether you call it a post-mortem, retrospective or debrief, build the habits and expertise to routinely examine the systemic component causes of failure. Try using Rothmans Causal Pies in your next incident review.
Run “fire drills” and disaster exercises. Make it easier for humans to deal with emergencies and unexpected events by making it habit. Increase the cognitive load available for problem solving in emergencies.
Structure the organisation in a way that facilitates adaptation and change. Consider appropriate team topologies to facilitate adaptability.
In summary
Through facilitating learning, responding, monitoring, and anticipating threats, we can create resilient organisations. DevOps and psychological safety are two important components of resilience engineering, and resilience engineering (in my opinion) is soon going to be seen as a core aspect of organisational (and digital) transformation.
References:
Conway, M. E. (1968) How Do Committees Invent? Datamation magazine. F. D. Thompson Publications, Inc. Available at: https://www.melconway.com/Home/Committees_Paper.html
Dekker, S. 2006. The Field Guide to Understanding Human Error. Ashgate Publishing Company, USA.
Edmondson, A., 1999. Psychological safety and learning behavior in work teams. Administrative science quarterly, 44(2), pp.350-383.
Garvin, David & Edmondson, Amy & Gino, Francesca. (2008). Is Yours a Learning Organization?. Harvard business review. 86. 109-16, 134.
Hochstein, L. (2019) Resilience engineering: Where do I start? Available at: https://github.com/lorin/resilience-engineering/blob/master/intro.md (Accessed: 17 November 2020).
Hollnagel, E., Woods, D. D. & Leveson, N. C. (2006). Resilience engineering: Concepts and precepts. Aldershot, UK: Ashgate.
Hollnagel, E. Resilience Engineering (2020). Available at: https://erikhollnagel.com/ideas/resilience-engineering.html (Accessed: 17 November 2020).
Provan, D.J., Woods, D.D., Dekker, S.W. and Rae, A.J., 2020. Safety II professionals: how resilience engineering can transform safety practice. Reliability Engineering & System Safety, 195, p.106740. Available at https://www.sciencedirect.com/science/article/pii/S0951832018309864
Woods, D. D. (2018). Resilience is a verb. In Trump, B. D., Florin, M.-V., & Linkov, I.
(Eds.). IRGC resource guide on resilience (vol. 2): Domains of resilience for complex interconnected systems. Lausanne, CH: EPFL International Risk Governance Center. Available on irgc.epfl.ch and irgc.org.
John Allspaw has collated an excellent book list for essential reading on resilience engineering here.